Run INSPIRE on the human DLPFC dataset (12 sections)
The spatial transcriptomics DLPFC data are publicly available at https://github.com/LieberInstitute/spatialLIBD.
Import packages
[1]:
import pandas as pd
import numpy as np
import scanpy as sc
import anndata as ad
import umap
import matplotlib.pyplot as plt
from matplotlib.cm import get_cmap
import INSPIRE
import warnings
warnings.filterwarnings("ignore")
Load data
[2]:
data_dir = "data/DLPFC/spatialLIBD"
slice_idx_list = [151673, 151674, 151675, 151676,
151507, 151508, 151509, 151510,
151672, 151671, 151670, 151669]
adata_st_list = []
for slice_idx in slice_idx_list:
adata_st = sc.read_visium(path=data_dir+"/%d" % slice_idx, count_file="%d_filtered_feature_bc_matrix.h5" % slice_idx)
anno_df = pd.read_csv(data_dir+'/barcode_level_layer_map.tsv', sep='\t', header=None)
anno_df = anno_df.iloc[anno_df[1].values.astype(str) == str(slice_idx)]
anno_df.columns = ["barcode", "slice_id", "layer"]
anno_df.index = anno_df['barcode']
adata_st.obs = adata_st.obs.join(anno_df, how="left")
adata_st = adata_st[adata_st.obs['layer'].notna()]
adata_st_add = adata_st.copy()
adata_st_add.var_names_make_unique()
adata_st_list.append(adata_st_add)
[3]:
adata_st_list, adata_full = INSPIRE.utils.preprocess(adata_st_list=adata_st_list,
num_hvgs=10000,
min_genes_qc=50,
min_cells_qc=50,
spot_size=100)
Finding highly variable genes...
shape of adata 0 before quality control: (3611, 33525)
shape of adata 0 after quality control: (3611, 13067)
shape of adata 1 before quality control: (3635, 33525)
shape of adata 1 after quality control: (3635, 13955)
shape of adata 2 before quality control: (3566, 33525)
shape of adata 2 after quality control: (3566, 12430)
shape of adata 3 before quality control: (3431, 33525)
shape of adata 3 after quality control: (3431, 12564)
shape of adata 4 before quality control: (4221, 33525)
shape of adata 4 after quality control: (4220, 11963)
shape of adata 5 before quality control: (4381, 33525)
shape of adata 5 after quality control: (4380, 11437)
shape of adata 6 before quality control: (4788, 33525)
shape of adata 6 after quality control: (4786, 12394)
shape of adata 7 before quality control: (4595, 33525)
shape of adata 7 after quality control: (4593, 12066)
shape of adata 8 before quality control: (3888, 33525)
shape of adata 8 after quality control: (3888, 12414)
shape of adata 9 before quality control: (4093, 33525)
shape of adata 9 after quality control: (4093, 12789)
shape of adata 10 before quality control: (3484, 33525)
shape of adata 10 after quality control: (3484, 11923)
shape of adata 11 before quality control: (3636, 33525)
shape of adata 11 after quality control: (3635, 12290)
Find 2681 shared highly variable genes among datasets.
Concatenate datasets as a full anndata for better visualization...

Store counts and library sizes for Poisson modeling...
Normalize data...
[4]:
sc.pl.spatial(adata_full, color="layer", spot_size=100)
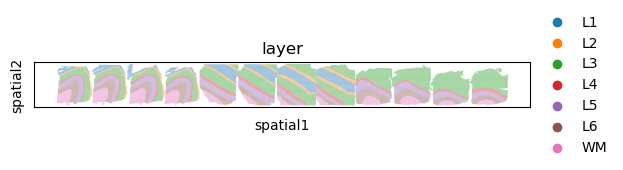
[5]:
adata_st_list = INSPIRE.utils.build_graph_GAT(adata_st_list=adata_st_list,
rad_coef=1.1)
Start building graphs...
Calculate radius cutoff based on 'rad_coef' and mininal distance between spots/cells within a dataset...
Radius for graph connection is 150.7000.
Build graphs for GAT networks
5.8261 neighbors per cell on average.
5.8140 neighbors per cell on average.
5.8015 neighbors per cell on average.
5.8193 neighbors per cell on average.
5.8649 neighbors per cell on average.
5.8630 neighbors per cell on average.
5.8801 neighbors per cell on average.
5.8720 neighbors per cell on average.
5.8565 neighbors per cell on average.
5.8563 neighbors per cell on average.
5.8381 neighbors per cell on average.
5.8102 neighbors per cell on average.
Run INSPIRE model
[6]:
model = INSPIRE.model.Model_GAT(adata_st_list=adata_st_list,
n_spatial_factors=20,
n_training_steps=10000,
use_margin=False,
)
[7]:
model.train()
0%| | 1/10000 [00:00<1:35:10, 1.75it/s]
Step: 0, d_loss: 15.3705, Loss: 22808.4746, recon_loss: 19677.8652, fe_loss: 479.7892, geom_loss: 6710.6357, beta_loss: 250.1640, gan_loss: 7.4837
5%|▌ | 501/10000 [02:39<50:24, 3.14it/s]
Step: 500, d_loss: 8.4142, Loss: 18688.6230, recon_loss: 15708.3359, fe_loss: 341.2279, geom_loss: 2015.9548, beta_loss: 255.3434, gan_loss: 22.6528
10%|█ | 1001/10000 [05:18<47:51, 3.13it/s]
Step: 1000, d_loss: 7.5748, Loss: 15827.8662, recon_loss: 12738.3818, fe_loss: 339.8287, geom_loss: 2210.7004, beta_loss: 265.6053, gan_loss: 24.6941
15%|█▌ | 1501/10000 [07:58<45:03, 3.14it/s]
Step: 1500, d_loss: 8.2047, Loss: 13941.6846, recon_loss: 10893.5957, fe_loss: 339.0390, geom_loss: 1886.6050, beta_loss: 262.1799, gan_loss: 24.7592
20%|██ | 2001/10000 [10:37<42:28, 3.14it/s]
Step: 2000, d_loss: 6.4627, Loss: 12862.8018, recon_loss: 9876.1660, fe_loss: 338.6111, geom_loss: 1656.6283, beta_loss: 256.5164, gan_loss: 24.8637
25%|██▌ | 2501/10000 [13:17<39:59, 3.13it/s]
Step: 2500, d_loss: 5.7250, Loss: 12314.2012, recon_loss: 9403.4268, fe_loss: 338.1010, geom_loss: 1846.8093, beta_loss: 248.2935, gan_loss: 26.4011
30%|███ | 3001/10000 [15:57<37:16, 3.13it/s]
Step: 3000, d_loss: 5.3382, Loss: 12040.3027, recon_loss: 9176.0742, fe_loss: 337.8644, geom_loss: 2021.2062, beta_loss: 243.1387, gan_loss: 27.2767
35%|███▌ | 3501/10000 [18:37<34:38, 3.13it/s]
Step: 3500, d_loss: 5.4608, Loss: 11911.0273, recon_loss: 9071.2500, fe_loss: 337.4735, geom_loss: 2140.1912, beta_loss: 240.5543, gan_loss: 26.9787
40%|████ | 4001/10000 [21:16<31:58, 3.13it/s]
Step: 4000, d_loss: 5.5585, Loss: 11856.9131, recon_loss: 9017.1035, fe_loss: 337.2610, geom_loss: 2187.2539, beta_loss: 240.0451, gan_loss: 29.1763
45%|████▌ | 4501/10000 [23:55<28:47, 3.18it/s]
Step: 4500, d_loss: 5.8741, Loss: 11826.1729, recon_loss: 8988.8467, fe_loss: 337.0001, geom_loss: 2338.5100, beta_loss: 239.8353, gan_loss: 27.6018
50%|█████ | 5001/10000 [26:33<26:11, 3.18it/s]
Step: 5000, d_loss: 5.8376, Loss: 11803.4229, recon_loss: 8968.7402, fe_loss: 336.8444, geom_loss: 2379.9775, beta_loss: 239.7458, gan_loss: 26.3900
55%|█████▌ | 5501/10000 [29:11<23:37, 3.17it/s]
Step: 5500, d_loss: 5.8725, Loss: 11790.4131, recon_loss: 8950.2363, fe_loss: 336.7567, geom_loss: 2349.9136, beta_loss: 239.7230, gan_loss: 29.5960
60%|██████ | 6001/10000 [31:48<20:58, 3.18it/s]
Step: 6000, d_loss: 6.8440, Loss: 11776.8789, recon_loss: 8938.7559, fe_loss: 336.6150, geom_loss: 2472.1353, beta_loss: 239.7934, gan_loss: 27.0660
65%|██████▌ | 6501/10000 [34:26<18:25, 3.16it/s]
Step: 6500, d_loss: 6.8139, Loss: 11772.7520, recon_loss: 8930.0508, fe_loss: 336.5599, geom_loss: 2663.1355, beta_loss: 239.7972, gan_loss: 27.4536
70%|███████ | 7001/10000 [37:04<15:48, 3.16it/s]
Step: 7000, d_loss: 6.4457, Loss: 11760.1455, recon_loss: 8923.0420, fe_loss: 336.4574, geom_loss: 2601.4607, beta_loss: 239.7146, gan_loss: 25.7359
75%|███████▌ | 7501/10000 [39:41<13:07, 3.17it/s]
Step: 7500, d_loss: 6.4339, Loss: 11755.7217, recon_loss: 8913.6660, fe_loss: 336.3817, geom_loss: 2892.9519, beta_loss: 239.8090, gan_loss: 24.8619
80%|████████ | 8001/10000 [42:19<10:29, 3.17it/s]
Step: 8000, d_loss: 6.3065, Loss: 11766.8330, recon_loss: 8905.4443, fe_loss: 336.3000, geom_loss: 3252.4446, beta_loss: 239.7855, gan_loss: 31.0921
85%|████████▌ | 8501/10000 [44:57<07:53, 3.17it/s]
Step: 8500, d_loss: 6.0182, Loss: 11760.8564, recon_loss: 8902.6982, fe_loss: 336.2878, geom_loss: 3370.2681, beta_loss: 239.7093, gan_loss: 28.6861
90%|█████████ | 9001/10000 [47:34<05:14, 3.18it/s]
Step: 9000, d_loss: 6.1647, Loss: 11766.7998, recon_loss: 8900.0635, fe_loss: 336.2672, geom_loss: 3778.1899, beta_loss: 239.7764, gan_loss: 28.5707
95%|█████████▌| 9501/10000 [50:12<02:36, 3.18it/s]
Step: 9500, d_loss: 5.9088, Loss: 11760.2031, recon_loss: 8895.9180, fe_loss: 336.1664, geom_loss: 3829.1467, beta_loss: 239.7111, gan_loss: 27.2128
100%|██████████| 10000/10000 [52:50<00:00, 3.15it/s]
[8]:
adata_full, basis_df = model.eval(adata_full)
basis = np.array(basis_df.values)
Add cell/spot proportions of spatial factors into adata_full.obs...
Add cell/spot latent representations into adata_full.obsm['latent']...
Spatial distributions of spatial factors in tissues
[9]:
sc.pl.spatial(adata_full, color=["Proportion of spatial factor "+str(i+1) for i in range(20)], spot_size=150.)

Spot representations and spatial domain identification
[10]:
# calculate 2D UMAP coordinate of spots based on INSPIRE's learned spot representations.
reducer = umap.UMAP(n_neighbors=50,
n_components=2,
metric="euclidean",
n_epochs=None,
learning_rate=1.0,
min_dist=0.3,
spread=1.0,
set_op_mix_ratio=1.0,
local_connectivity=1,
repulsion_strength=1,
negative_sample_rate=5,
a=None,
b=None,
random_state=1234,
metric_kwds=None,
angular_rp_forest=False,
verbose=True)
embedding = reducer.fit_transform(adata_full.obsm['latent'])
adata_full.obsm["X_umap"] = embedding
adata_full.obs["slice"] = adata_full.obs["slice"].values.astype(str)
UMAP(local_connectivity=1, min_dist=0.3, n_neighbors=50, random_state=1234, repulsion_strength=1, verbose=True)
Wed May 27 16:16:29 2026 Construct fuzzy simplicial set
Wed May 27 16:16:29 2026 Finding Nearest Neighbors
Wed May 27 16:16:29 2026 Building RP forest with 16 trees
Wed May 27 16:16:32 2026 NN descent for 16 iterations
1 / 16
2 / 16
Stopping threshold met -- exiting after 2 iterations
Wed May 27 16:16:45 2026 Finished Nearest Neighbor Search
Wed May 27 16:16:48 2026 Construct embedding
completed 0 / 200 epochs
completed 20 / 200 epochs
completed 40 / 200 epochs
completed 60 / 200 epochs
completed 80 / 200 epochs
completed 100 / 200 epochs
completed 120 / 200 epochs
completed 140 / 200 epochs
completed 160 / 200 epochs
completed 180 / 200 epochs
Wed May 27 16:17:40 2026 Finished embedding
[11]:
adata_full.obs["sample"] = ""
adata_full.obs["sample"][adata_full.obs["slice_id"].isin([151673.0, 151674.0, 151675.0, 151676.0])] = "sample 1"
adata_full.obs["sample"][adata_full.obs["slice_id"].isin([151507.0, 151508.0, 151509.0, 151510.0])] = "sample 2"
adata_full.obs["sample"][adata_full.obs["slice_id"].isin([151669.0, 151670.0, 151671.0, 151672.0])] = "sample 3"
sc.pl.umap(adata_full, color=["sample"])
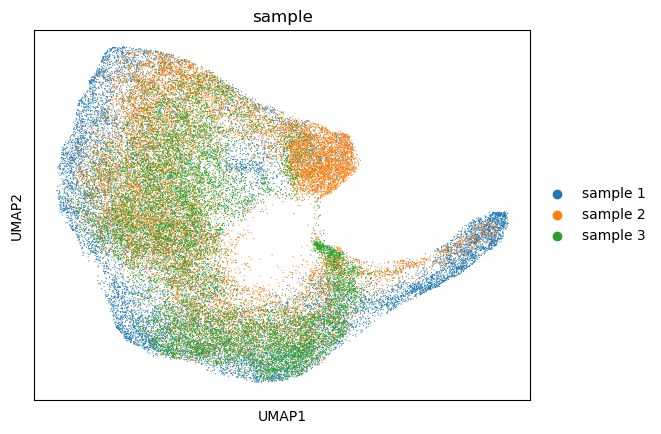
[12]:
# perform clustering on spot representations (spatial domain identification)
from sklearn.mixture import GaussianMixture
np.random.seed(12)
gm = GaussianMixture(n_components=7, covariance_type='tied', init_params='kmeans')
# gm = GaussianMixture(n_components=7, covariance_type='spherical', init_params='kmeans')
y = gm.fit_predict(adata_full.obsm['latent'], y=None)
adata_full.obs["GM"] = y
sc.pl.umap(adata_full, color=["layer", "GM", "slice"])
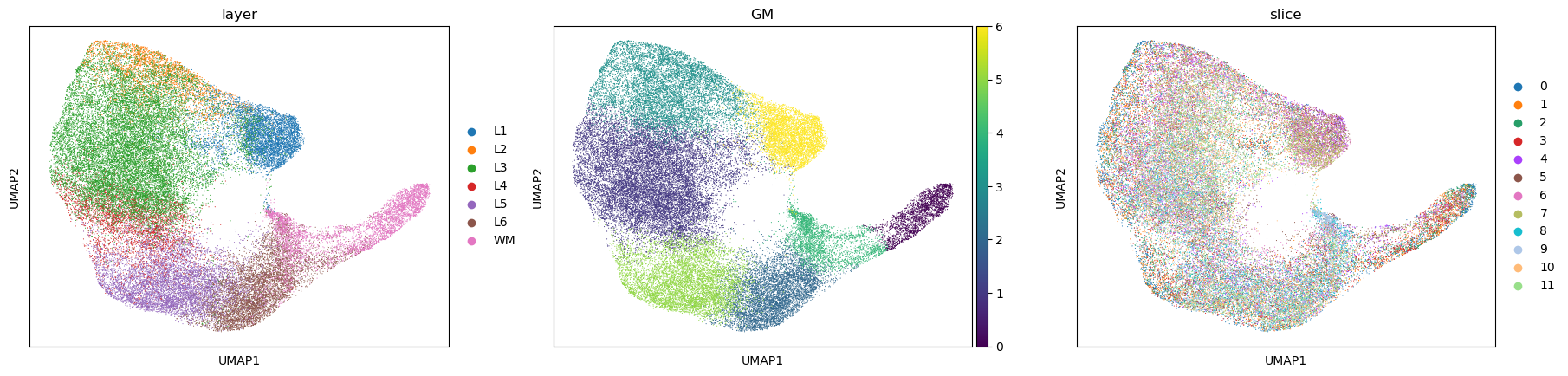
[13]:
colors = [i for i in get_cmap('Set3').colors]
size = .1
f = plt.figure(figsize=(10,5))
ax = f.add_subplot(1,1,1)
ax.axis('equal')
for i in range(len(set(adata_full.obs["GM"]))):
ax.scatter(adata_full.obsm["spatial"][adata_full.obs["GM"].values.astype(str)==str(i), 0],
-adata_full.obsm["spatial"][adata_full.obs["GM"].values.astype(str)==str(i), 1],
s=size, color=colors[i], label="cluster "+str(i))
ax.tick_params(axis='both',bottom=False, top=False, left=False, right=False, labelleft=False, labelbottom=False, grid_alpha=0)
plt.show()

[14]:
n_slices = len(set(adata_full.obs.slice.values))
Spot representation scores
[15]:
# ASW
for i in range(n_slices):
adata_tmp = adata_full[adata_full.obs.slice.values.astype(str) == str(i), :]
ASW = INSPIRE.utils.calculate_ASW(adata_tmp.obsm["latent"], adata_tmp.obs["layer"].astype(str))
print("slice", str(i), "ASW =", ASW)
slice 0 ASW = 0.23197548
slice 1 ASW = 0.24192268
slice 2 ASW = 0.22492354
slice 3 ASW = 0.2216665
slice 4 ASW = 0.18352832
slice 5 ASW = 0.15420167
slice 6 ASW = 0.1761681
slice 7 ASW = 0.17795514
slice 8 ASW = 0.15332146
slice 9 ASW = 0.15149578
slice 10 ASW = 0.06571517
slice 11 ASW = 0.11021188
[16]:
# ARI
for i in range(n_slices):
adata_tmp = adata_full[adata_full.obs.slice.values.astype(str) == str(i), :]
ARI = INSPIRE.utils.calculate_ARI(adata_tmp.obs["layer"].astype(str), adata_tmp.obs["GM"])
print("slice", str(i), "ARI =", ARI)
slice 0 ARI = 0.5600348091339422
slice 1 ARI = 0.5468529614240895
slice 2 ARI = 0.5137500197821184
slice 3 ARI = 0.5181052446433895
slice 4 ARI = 0.548919916550783
slice 5 ARI = 0.5232734993786468
slice 6 ARI = 0.5442013715152354
slice 7 ARI = 0.5540827274679454
slice 8 ARI = 0.6090622409395503
slice 9 ARI = 0.61829991925835
slice 10 ARI = 0.38298653498501634
slice 11 ARI = 0.40187290374221163
[17]:
# NMI
for i in range(n_slices):
adata_tmp = adata_full[adata_full.obs.slice.values.astype(str) == str(i), :]
NMI = INSPIRE.utils.calculate_NMI(adata_tmp.obs["layer"].astype(str), adata_tmp.obs["GM"])
print("slice", str(i), "NMI =", NMI)
slice 0 NMI = 0.6769302842353887
slice 1 NMI = 0.6733260310174889
slice 2 NMI = 0.6561158880430559
slice 3 NMI = 0.6549891027415284
slice 4 NMI = 0.6807751961993169
slice 5 NMI = 0.6545039696759388
slice 6 NMI = 0.6595679645196831
slice 7 NMI = 0.652333342869043
slice 8 NMI = 0.6715646717474638
slice 9 NMI = 0.6774578435076237
slice 10 NMI = 0.5338836138723728
slice 11 NMI = 0.5651163172925143
Factor scores
[18]:
basis = np.array(basis_df.values)
[19]:
# factor diversity
factor_diversity = INSPIRE.utils.calculate_factor_diversity(basis, n_top_genes=10)
print("factor_diversity =", factor_diversity)
factor_diversity = 0.385
[20]:
adata_raw = adata_full[:, basis_df.columns]
# factor coherence
factor_coherence = INSPIRE.utils.calculate_factor_coherence(basis, n_top_genes=10, gene_counts=np.array(adata_raw.X.todense()))
print("factor_coherence =", factor_coherence)
factor_coherence = 0.11233645447205719
[ ]: