Using INSPIRE with lightweight graph convolutional networks (LGCNs)
INSPIRE provides two integrative analyses options: one based on graph attention networks (GATs) and the other on lightweight graph convolutional networks (LGCNs). For tissue sections profiled using low-resolution platforms such as Visium or ST, we recommend employing the graph attention network variant of INSPIRE to leverage the attention mechanism for improved modeling accuracy. For high-resolution datasets, the lightweight graph convolutional network variant is recommended, as it provides enhanced computational efficiency and scalability for large-scale analyses.
We use the integrative analysis of mouse whole-embryo sections profiled by seqFISH and Stereo-seq as an example to provide step-by-step instructions for applying INSPIRE with lightweight graph convolutional networks (LGCNs).
Import packages
[1]:
import numpy as np
import scanpy as sc
import umap
import INSPIRE
import warnings
warnings.filterwarnings("ignore")
Load data
The input to INSPIRE consists of raw gene expression count matrices and spatial coordinate matrices derived from multiple tissue sections, with each section represented as an individual AnnData object. Specifically, for each tissue section, the raw count matrix is stored in adata.X, and the spatial coordinates of the spatial spots are stored in adata.obsm[“spatial”].
The example seqFISH and Stereo-seq tissue sections used in this tutorial can be downloaded from https://drive.google.com/drive/folders/1fBVZiUnUEa31-P7AMmDyQ5UPU58VnIox?usp=sharing.
[2]:
data_dir = "/gpfs/gibbs/pi/zhao/jz874/project/jiazhao/inspire_revision/tutorials/example_analyses/example_LGCN_data"
adata_seqfish = sc.read_h5ad(data_dir + "/adata_seqfish.h5ad")
adata_stereoseq = sc.read_h5ad(data_dir + "/adata_stereoseq.h5ad")
adata_st_list = [adata_seqfish, adata_stereoseq]
Data preprocessing
For integrative analyses involving sections with a limited number of shared measured genes, we recommend removing non-shared genes prior to selecting num_hvgs highly variable genes per section by setting limit_num_genes=True. In this example, only 347 genes are shared between the seqFISH and Stereo-seq sections. As a result, no further feature selection is necessary, and num_hvgs is set to a value higher than the number of shared genes to avoid additional filtering. Users may adjust quality control thresholds by modifying the min_genes_qc and min_cell_qc parameters. Setting both parameters to 2 generally yields satisfactory performance when integrating sections with a limited number of shared genes. The spot_size parameter is used exclusively for visualization and determines the size of each spatial spot in the generated plots.
[3]:
adata_st_list, adata_full = INSPIRE.utils.preprocess(adata_st_list=adata_st_list,
num_hvgs=1000,
min_genes_qc=2,
min_cells_qc=2,
spot_size=1,
limit_num_genes=True)
Get shared genes among all datasets...
Find 347 shared genes among datasets.
Finding highly variable genes...
shape of adata 0 before quality control: (14185, 347)
shape of adata 0 after quality control: (14185, 347)
shape of adata 1 before quality control: (5913, 347)
shape of adata 1 after quality control: (5880, 344)
Find 344 shared highly variable genes among datasets.
Concatenate datasets as a full anndata for better visualization...
Store counts and library sizes for Poisson modeling...
Normalize data...
Build spatial graph
INSPIRE constructs a spatial neighbor graph among spots to model spatial dependencies within each tissue section. When using the lightweight graph convolutional network (LGCN) variant, this graph is built using the INSPIRE.utils.build_graph_LGCN function, which accepts adata_st_list as input. Users can customize the radius cutoff for defining spatial neighbors in each section by modifying the values in rad_cutoff_list. In this example, we define eight natural neighbors per spot in the seqFISH section by setting the corresponding radius cutoff to 1.6. To account for differences in the scale of spatial coordinates between the two sections, we adjust the cutoff accordingly and use a value of 3 for defining spatial neighbors in the Stereo-seq section.
[4]:
adata_st_list = INSPIRE.utils.build_graph_LGCN(adata_st_list=adata_st_list,
rad_cutoff_list=[3,1.6])
Start building graphs...
Build graphs and prepare node features for LGCN networks
Radius for graph connection is 3.0000.
26.7748 neighbors per cell on average.
Node features for slice 0 : (14185, 688)
Radius for graph connection is 1.6000.
7.7946 neighbors per cell on average.
Node features for slice 1 : (5880, 688)
Run INSPIRE model
The computational model for the LGCN variant of INSPIRE is constructed using the INSPIRE.model.Model_LGCN function, which takes adata_st_list as input. Four key parameters of this function include n_spatial_factors, n_training_steps, batch_size, and different_platforms. The n_spatial_factors parameter specifies the number of spatial factors to be inferred and should be selected based on the complexity of the tissue. A default setting of n_training_steps = 10,000 typically provides robust results. Increasing this value to 20,000 may be advantageous when modeling a larger number of spatial factors. For integrative analyses involving more than 20,000 cells or spots, we recommend setting batch_size = 2048. For datasets with fewer than 20,000 cells or spots, batch_size = 1024 is typically sufficient. The different_platforms parameter determines whether section-specific networks are used to generate spatial factors from cell or spot embeddings. When analyzing sections derived from different technologies, where strong platform-specific effects are expected, we recommend setting different_platforms = True. In all other cases, the default setting is False.
[6]:
model = INSPIRE.model.Model_LGCN(adata_st_list=adata_st_list,
n_spatial_factors=40,
n_training_steps=10000,
batch_size=2048,
different_platforms=True
)
After constructing the computational model, training is performed using the model.train function.
[7]:
model.train(adata_st_list)
0%| | 6/10000 [00:00<08:30, 19.58it/s]
Step: 0, d_loss: 1.4992, Loss: 1364.8623, recon_loss: 552.5065, fe_loss: 44.9286, geom_loss: 165.7725, beta_loss: 763.3344, gan_loss: 0.7776
5%|▌ | 506/10000 [00:12<03:39, 43.26it/s]
Step: 500, d_loss: 0.6237, Loss: 1167.3342, recon_loss: 433.0272, fe_loss: 28.1169, geom_loss: 87.4508, beta_loss: 702.1931, gan_loss: 2.2480
10%|█ | 1006/10000 [00:23<03:29, 42.98it/s]
Step: 1000, d_loss: 0.3045, Loss: 1076.6626, recon_loss: 341.4729, fe_loss: 27.3702, geom_loss: 130.6975, beta_loss: 701.8184, gan_loss: 3.3872
15%|█▌ | 1506/10000 [00:35<03:18, 42.72it/s]
Step: 1500, d_loss: 0.2098, Loss: 1014.6364, recon_loss: 279.4295, fe_loss: 26.9022, geom_loss: 131.7953, beta_loss: 701.8845, gan_loss: 3.7844
20%|██ | 2006/10000 [00:47<03:02, 43.78it/s]
Step: 2000, d_loss: 0.2105, Loss: 973.4398, recon_loss: 237.6814, fe_loss: 26.6580, geom_loss: 124.8234, beta_loss: 702.2662, gan_loss: 4.3377
25%|██▌ | 2506/10000 [00:59<02:52, 43.38it/s]
Step: 2500, d_loss: 0.2238, Loss: 949.7872, recon_loss: 214.8734, fe_loss: 26.5242, geom_loss: 119.8150, beta_loss: 702.2215, gan_loss: 3.7718
30%|███ | 3006/10000 [01:10<02:39, 43.90it/s]
Step: 3000, d_loss: 0.1744, Loss: 928.3311, recon_loss: 194.4388, fe_loss: 26.3288, geom_loss: 109.8261, beta_loss: 701.8584, gan_loss: 3.5087
35%|███▌ | 3506/10000 [01:22<02:30, 43.27it/s]
Step: 3500, d_loss: 0.1483, Loss: 922.0637, recon_loss: 187.6211, fe_loss: 26.2629, geom_loss: 105.1442, beta_loss: 701.8630, gan_loss: 4.2138
40%|████ | 4006/10000 [01:34<02:18, 43.14it/s]
Step: 4000, d_loss: 0.2480, Loss: 909.9057, recon_loss: 176.3834, fe_loss: 26.1227, geom_loss: 100.0805, beta_loss: 701.8671, gan_loss: 3.5309
45%|████▌ | 4506/10000 [01:45<02:05, 43.72it/s]
Step: 4500, d_loss: 0.2300, Loss: 910.6376, recon_loss: 177.2427, fe_loss: 26.1271, geom_loss: 98.9051, beta_loss: 701.7460, gan_loss: 3.5437
50%|█████ | 5006/10000 [01:57<01:58, 42.19it/s]
Step: 5000, d_loss: 0.3022, Loss: 901.6885, recon_loss: 167.7816, fe_loss: 26.0828, geom_loss: 99.3437, beta_loss: 701.8264, gan_loss: 4.0109
55%|█████▌ | 5506/10000 [02:09<01:47, 41.78it/s]
Step: 5500, d_loss: 0.2461, Loss: 903.7646, recon_loss: 170.3498, fe_loss: 26.1392, geom_loss: 91.4499, beta_loss: 701.7339, gan_loss: 3.7127
60%|██████ | 6006/10000 [02:20<01:33, 42.82it/s]
Step: 6000, d_loss: 0.2192, Loss: 896.4146, recon_loss: 163.2331, fe_loss: 26.1898, geom_loss: 88.4344, beta_loss: 701.5472, gan_loss: 3.6757
65%|██████▌ | 6506/10000 [02:32<01:25, 40.75it/s]
Step: 6500, d_loss: 0.2820, Loss: 899.3956, recon_loss: 166.6798, fe_loss: 26.2029, geom_loss: 80.5115, beta_loss: 701.5717, gan_loss: 3.3311
70%|███████ | 7006/10000 [02:44<01:08, 43.64it/s]
Step: 7000, d_loss: 0.2347, Loss: 890.3608, recon_loss: 158.0955, fe_loss: 26.1279, geom_loss: 76.1080, beta_loss: 701.5854, gan_loss: 3.0298
75%|███████▌ | 7506/10000 [02:55<00:59, 42.17it/s]
Step: 7500, d_loss: 0.2511, Loss: 889.9950, recon_loss: 157.2804, fe_loss: 26.1080, geom_loss: 72.4438, beta_loss: 701.7313, gan_loss: 3.4264
80%|████████ | 8006/10000 [03:07<00:45, 43.52it/s]
Step: 8000, d_loss: 0.2183, Loss: 889.2778, recon_loss: 156.7681, fe_loss: 26.1152, geom_loss: 71.1025, beta_loss: 701.6929, gan_loss: 3.2796
85%|████████▌ | 8506/10000 [03:19<00:34, 42.71it/s]
Step: 8500, d_loss: 0.2201, Loss: 883.6912, recon_loss: 151.7068, fe_loss: 26.0463, geom_loss: 66.4949, beta_loss: 701.5209, gan_loss: 3.0872
90%|█████████ | 9006/10000 [03:31<00:24, 41.10it/s]
Step: 9000, d_loss: 0.2291, Loss: 884.2099, recon_loss: 151.7741, fe_loss: 26.0731, geom_loss: 65.6530, beta_loss: 701.6666, gan_loss: 3.3829
95%|█████████▌| 9506/10000 [03:42<00:11, 43.67it/s]
Step: 9500, d_loss: 0.2348, Loss: 883.2949, recon_loss: 151.3600, fe_loss: 26.0523, geom_loss: 62.8923, beta_loss: 701.4165, gan_loss: 3.2083
100%|██████████| 10000/10000 [03:54<00:00, 42.66it/s]
Access spot representations, proportions of spatial factors in spots, and gene loading matrix
After training the model, INSPIRE infers latent representations of spatial spots, spatial factors, and gene loadings using the model.eval function. This function returns two main outputs: adata_full and basis_df. The inferred latent representations of spatial spots are stored in adata_full.obsm[‘latent’], while the metadata indicating the section origin of each spot is saved in adata_full.obs. The spatial factor values assigned to individual spots are also stored in adata_full.obs, where adata_full.obs[“Proportion of spatial factor i”] contains the proportion values corresponding to spatial factor i across all analyzed spots. The inferred gene loading matrix, shared across sections, is saved in basis_df, which is a data frame with spatial factors as rows and genes as columns.
[8]:
adata_full, basis_df = model.eval(adata_st_list, adata_full)
basis = np.array(basis_df.values)
Add cell/spot proportions of spatial factors into adata_full.obs...
Add cell/spot latent representations into adata_full.obsm['latent']...
[9]:
basis_df
[9]:
| Abcc4 | Acp5 | Acvr1 | Acvr2a | Adora2b | Afp | Ahnak | Akr1c19 | Alas2 | Aldh1a2 | ... | Wnt2 | Wnt2b | Wnt3 | Wnt3a | Wnt5a | Wnt5b | Xist | Zfp444 | Zfp57 | Zic3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.001891 | 0.001366 | 0.002146 | 0.004803 | 0.002764 | 0.000217 | 0.010406 | 0.002019 | 0.001362 | 0.000272 | ... | 0.001283 | 0.004060 | 0.002781 | 0.001003 | 0.001812 | 0.001912 | 0.005055 | 0.002338 | 0.004687 | 0.000627 |
| 1 | 0.003183 | 0.002417 | 0.003011 | 0.004382 | 0.001082 | 0.000150 | 0.002989 | 0.000668 | 0.001464 | 0.000549 | ... | 0.000207 | 0.001333 | 0.000405 | 0.000318 | 0.001675 | 0.003486 | 0.002006 | 0.003549 | 0.002554 | 0.000395 |
| 2 | 0.004902 | 0.000600 | 0.003478 | 0.002555 | 0.002423 | 0.000247 | 0.000607 | 0.002346 | 0.000360 | 0.000188 | ... | 0.000831 | 0.000727 | 0.001466 | 0.000815 | 0.006010 | 0.003184 | 0.005976 | 0.004026 | 0.001342 | 0.000686 |
| 3 | 0.000912 | 0.000695 | 0.001673 | 0.003136 | 0.001766 | 0.000839 | 0.001595 | 0.004923 | 0.000549 | 0.000417 | ... | 0.008992 | 0.001814 | 0.001504 | 0.001638 | 0.001265 | 0.001916 | 0.002699 | 0.003017 | 0.003812 | 0.001313 |
| 4 | 0.000860 | 0.000530 | 0.001736 | 0.004526 | 0.002501 | 0.000344 | 0.002866 | 0.001399 | 0.000554 | 0.001668 | ... | 0.000276 | 0.001178 | 0.000598 | 0.000327 | 0.001315 | 0.002891 | 0.002523 | 0.003816 | 0.006548 | 0.003307 |
| 5 | 0.001532 | 0.000907 | 0.003049 | 0.002254 | 0.000339 | 0.000186 | 0.010012 | 0.001599 | 0.000365 | 0.000450 | ... | 0.011739 | 0.001445 | 0.000424 | 0.000426 | 0.005618 | 0.002162 | 0.002492 | 0.001161 | 0.004623 | 0.000281 |
| 6 | 0.001340 | 0.027123 | 0.001011 | 0.001217 | 0.000822 | 0.000343 | 0.001018 | 0.000870 | 0.032075 | 0.000470 | ... | 0.001075 | 0.000731 | 0.000899 | 0.000899 | 0.000973 | 0.000759 | 0.001524 | 0.001717 | 0.000582 | 0.000385 |
| 7 | 0.001057 | 0.000748 | 0.002722 | 0.001763 | 0.002222 | 0.000770 | 0.005217 | 0.002182 | 0.000560 | 0.000417 | ... | 0.008314 | 0.001125 | 0.001206 | 0.001413 | 0.004243 | 0.001064 | 0.002376 | 0.002056 | 0.001966 | 0.001516 |
| 8 | 0.001288 | 0.000757 | 0.002876 | 0.001986 | 0.000985 | 0.000337 | 0.000235 | 0.002018 | 0.000598 | 0.040546 | ... | 0.000919 | 0.001234 | 0.001538 | 0.000568 | 0.002146 | 0.002673 | 0.002899 | 0.003108 | 0.002873 | 0.000436 |
| 9 | 0.001699 | 0.000830 | 0.002196 | 0.002979 | 0.002057 | 0.000231 | 0.008899 | 0.005001 | 0.001022 | 0.000505 | ... | 0.001070 | 0.000792 | 0.003840 | 0.001498 | 0.003215 | 0.001984 | 0.001237 | 0.003833 | 0.001507 | 0.000757 |
| 10 | 0.001731 | 0.001682 | 0.002734 | 0.001823 | 0.001336 | 0.000367 | 0.003338 | 0.002492 | 0.000605 | 0.000668 | ... | 0.001000 | 0.000854 | 0.001700 | 0.001182 | 0.000990 | 0.000651 | 0.002297 | 0.001618 | 0.003680 | 0.000847 |
| 11 | 0.003167 | 0.000366 | 0.002607 | 0.004497 | 0.000936 | 0.000140 | 0.000403 | 0.000802 | 0.000433 | 0.000195 | ... | 0.000509 | 0.001600 | 0.010185 | 0.019761 | 0.001492 | 0.002182 | 0.003328 | 0.002426 | 0.001706 | 0.006896 |
| 12 | 0.000831 | 0.001052 | 0.003102 | 0.004194 | 0.001321 | 0.000355 | 0.000834 | 0.001147 | 0.000276 | 0.009252 | ... | 0.001238 | 0.001730 | 0.000706 | 0.000474 | 0.004099 | 0.002161 | 0.001557 | 0.003819 | 0.003493 | 0.018908 |
| 13 | 0.001001 | 0.000537 | 0.003272 | 0.004739 | 0.000433 | 0.000318 | 0.000441 | 0.001158 | 0.000237 | 0.000340 | ... | 0.000561 | 0.003940 | 0.002967 | 0.002766 | 0.008093 | 0.005610 | 0.002654 | 0.005844 | 0.001636 | 0.009735 |
| 14 | 0.003780 | 0.000823 | 0.003053 | 0.002454 | 0.002668 | 0.000112 | 0.000994 | 0.001389 | 0.000547 | 0.000418 | ... | 0.000501 | 0.001340 | 0.000911 | 0.000584 | 0.016413 | 0.005847 | 0.002365 | 0.006627 | 0.003650 | 0.000948 |
| 15 | 0.002260 | 0.003124 | 0.001896 | 0.005446 | 0.002212 | 0.000678 | 0.006268 | 0.006401 | 0.001429 | 0.000672 | ... | 0.001024 | 0.001725 | 0.002718 | 0.001499 | 0.001896 | 0.004019 | 0.004406 | 0.003709 | 0.002559 | 0.001929 |
| 16 | 0.000809 | 0.000398 | 0.002962 | 0.002126 | 0.001388 | 0.000122 | 0.002413 | 0.000964 | 0.000421 | 0.000384 | ... | 0.004666 | 0.001220 | 0.000990 | 0.000399 | 0.002794 | 0.002913 | 0.002197 | 0.001869 | 0.002338 | 0.000207 |
| 17 | 0.001279 | 0.002426 | 0.005357 | 0.002301 | 0.001675 | 0.057006 | 0.002487 | 0.007357 | 0.000868 | 0.000867 | ... | 0.002189 | 0.001427 | 0.001068 | 0.000683 | 0.000765 | 0.001902 | 0.002651 | 0.003763 | 0.002250 | 0.000579 |
| 18 | 0.001737 | 0.001507 | 0.002164 | 0.003994 | 0.003465 | 0.000995 | 0.000549 | 0.005668 | 0.001914 | 0.000373 | ... | 0.001244 | 0.001375 | 0.002700 | 0.001576 | 0.001211 | 0.000876 | 0.002931 | 0.003631 | 0.001746 | 0.001963 |
| 19 | 0.001879 | 0.000655 | 0.001942 | 0.005235 | 0.004204 | 0.000143 | 0.005212 | 0.003036 | 0.001646 | 0.000230 | ... | 0.000539 | 0.002247 | 0.001090 | 0.000544 | 0.007391 | 0.004214 | 0.002895 | 0.003082 | 0.004702 | 0.000887 |
| 20 | 0.003214 | 0.001942 | 0.002438 | 0.002562 | 0.000483 | 0.000137 | 0.004137 | 0.000827 | 0.000731 | 0.000222 | ... | 0.000828 | 0.002340 | 0.007363 | 0.032066 | 0.000778 | 0.004229 | 0.001176 | 0.004002 | 0.004859 | 0.030024 |
| 21 | 0.001447 | 0.001041 | 0.002271 | 0.001449 | 0.001502 | 0.001549 | 0.002921 | 0.004316 | 0.000755 | 0.000455 | ... | 0.000543 | 0.001693 | 0.002291 | 0.000912 | 0.001149 | 0.001605 | 0.001703 | 0.004567 | 0.001377 | 0.001328 |
| 22 | 0.002555 | 0.000866 | 0.002141 | 0.005424 | 0.001019 | 0.000225 | 0.000489 | 0.005923 | 0.000619 | 0.000324 | ... | 0.000679 | 0.004510 | 0.001501 | 0.000830 | 0.002019 | 0.008841 | 0.003899 | 0.005046 | 0.001596 | 0.004279 |
| 23 | 0.001866 | 0.002413 | 0.003193 | 0.001704 | 0.004192 | 0.000111 | 0.013522 | 0.000331 | 0.003425 | 0.000319 | ... | 0.000341 | 0.001699 | 0.001133 | 0.001539 | 0.000988 | 0.003211 | 0.001061 | 0.002296 | 0.001893 | 0.002525 |
| 24 | 0.002995 | 0.000405 | 0.002249 | 0.003377 | 0.001469 | 0.000149 | 0.000959 | 0.001653 | 0.000470 | 0.000209 | ... | 0.000706 | 0.000790 | 0.000701 | 0.000605 | 0.002988 | 0.002924 | 0.001640 | 0.004695 | 0.003868 | 0.000563 |
| 25 | 0.006822 | 0.001068 | 0.001631 | 0.003223 | 0.001621 | 0.000303 | 0.002495 | 0.003249 | 0.000634 | 0.003525 | ... | 0.001089 | 0.001866 | 0.001219 | 0.000927 | 0.002491 | 0.003716 | 0.004975 | 0.008303 | 0.003237 | 0.000480 |
| 26 | 0.001232 | 0.000865 | 0.001737 | 0.000964 | 0.001881 | 0.000205 | 0.000842 | 0.001223 | 0.000408 | 0.001893 | ... | 0.001134 | 0.001148 | 0.001016 | 0.000617 | 0.000831 | 0.001163 | 0.002253 | 0.001762 | 0.003295 | 0.000916 |
| 27 | 0.001632 | 0.000963 | 0.002545 | 0.003741 | 0.002016 | 0.000161 | 0.003016 | 0.002040 | 0.000504 | 0.000191 | ... | 0.000671 | 0.000552 | 0.000618 | 0.000315 | 0.003914 | 0.001268 | 0.002297 | 0.004421 | 0.002323 | 0.000438 |
| 28 | 0.001044 | 0.000878 | 0.001356 | 0.000682 | 0.000644 | 0.000175 | 0.031114 | 0.001534 | 0.000844 | 0.000163 | ... | 0.003590 | 0.004340 | 0.001056 | 0.001455 | 0.004607 | 0.001219 | 0.000744 | 0.001378 | 0.001118 | 0.000513 |
| 29 | 0.000764 | 0.000551 | 0.002136 | 0.002169 | 0.001185 | 0.000237 | 0.000593 | 0.005202 | 0.000336 | 0.016792 | ... | 0.001304 | 0.001373 | 0.001166 | 0.001748 | 0.008200 | 0.003369 | 0.002557 | 0.003931 | 0.002888 | 0.000286 |
| 30 | 0.002445 | 0.000769 | 0.001065 | 0.002443 | 0.001933 | 0.000366 | 0.002514 | 0.005280 | 0.000435 | 0.007416 | ... | 0.000819 | 0.004649 | 0.002180 | 0.001244 | 0.010177 | 0.001059 | 0.004682 | 0.004578 | 0.002477 | 0.001315 |
| 31 | 0.001232 | 0.001937 | 0.001890 | 0.004328 | 0.000917 | 0.000538 | 0.005511 | 0.004348 | 0.000418 | 0.000213 | ... | 0.002603 | 0.003434 | 0.001291 | 0.001248 | 0.003663 | 0.002178 | 0.005222 | 0.002843 | 0.002514 | 0.000831 |
| 32 | 0.002137 | 0.000898 | 0.004264 | 0.005771 | 0.000868 | 0.000680 | 0.000874 | 0.000611 | 0.000658 | 0.000337 | ... | 0.000494 | 0.000854 | 0.002000 | 0.001049 | 0.000481 | 0.000852 | 0.001633 | 0.003443 | 0.002517 | 0.002292 |
| 33 | 0.005397 | 0.000433 | 0.003048 | 0.004035 | 0.001920 | 0.000203 | 0.000263 | 0.003862 | 0.000423 | 0.000468 | ... | 0.001010 | 0.000566 | 0.001718 | 0.000340 | 0.001793 | 0.010490 | 0.002119 | 0.004648 | 0.001898 | 0.014962 |
| 34 | 0.002471 | 0.001630 | 0.006478 | 0.002972 | 0.002530 | 0.000552 | 0.001293 | 0.000616 | 0.000842 | 0.000464 | ... | 0.001677 | 0.001442 | 0.001274 | 0.000907 | 0.000967 | 0.008255 | 0.001441 | 0.002773 | 0.004622 | 0.001387 |
| 35 | 0.002488 | 0.002157 | 0.002969 | 0.003047 | 0.000747 | 0.001007 | 0.000770 | 0.000437 | 0.000334 | 0.014770 | ... | 0.000810 | 0.000964 | 0.000810 | 0.002517 | 0.000800 | 0.001824 | 0.001311 | 0.002872 | 0.001096 | 0.001127 |
| 36 | 0.000609 | 0.002343 | 0.006526 | 0.002191 | 0.000434 | 0.000558 | 0.002223 | 0.000924 | 0.000708 | 0.000572 | ... | 0.004664 | 0.000579 | 0.000662 | 0.000248 | 0.003463 | 0.000928 | 0.001550 | 0.001739 | 0.002264 | 0.000209 |
| 37 | 0.019623 | 0.001587 | 0.002778 | 0.003041 | 0.001801 | 0.000373 | 0.000391 | 0.000883 | 0.000321 | 0.000282 | ... | 0.001410 | 0.000724 | 0.001440 | 0.001443 | 0.004026 | 0.006185 | 0.004489 | 0.004326 | 0.002361 | 0.001828 |
| 38 | 0.001220 | 0.006874 | 0.001400 | 0.002273 | 0.000631 | 0.000157 | 0.012084 | 0.001513 | 0.004599 | 0.019365 | ... | 0.016859 | 0.000850 | 0.001107 | 0.000362 | 0.000793 | 0.002272 | 0.000849 | 0.002893 | 0.001685 | 0.000210 |
| 39 | 0.001590 | 0.000357 | 0.003080 | 0.005897 | 0.001891 | 0.000161 | 0.000612 | 0.000347 | 0.000420 | 0.000233 | ... | 0.000512 | 0.000804 | 0.001405 | 0.000278 | 0.002522 | 0.002951 | 0.002390 | 0.004272 | 0.003145 | 0.000332 |
40 rows × 344 columns
Spatial distributions of spatial factors in tissues
The proportion values corresponding to spatial factors across all analyzed spots are stored in adata_full.obs. These spatial patterns can be visualized using the sc.pl.spatial function from the Scanpy pipeline. The spot_size parameter controls the size of each spatial spot in the resulting plots.
[10]:
sc.pl.spatial(adata_full, color=["Proportion of spatial factor "+str(i+1) for i in range(40)], spot_size=1.)

Spot representations and spatial domain identification
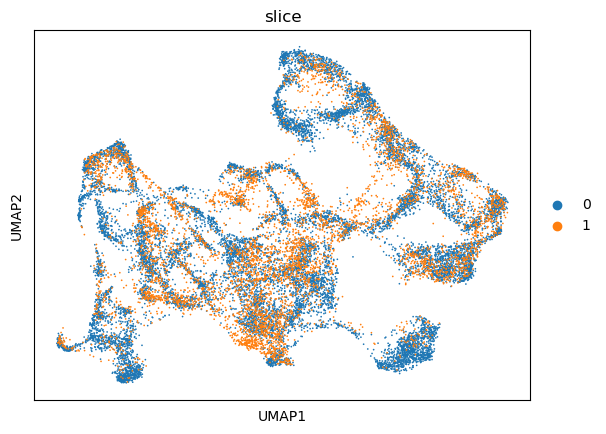
To visualize the spot representations learned by INSPIRE, we employ UMAP plots. The UMAP embedding is generated by first constructing a UMAP model using umap.UMAP, and then transforming the spot representations into two-dimensional coordinates using the fit_transform function from the umap package.
[11]:
reducer = umap.UMAP(n_neighbors=30,
n_components=2,
metric="correlation",
n_epochs=None,
learning_rate=1.0,
min_dist=0.3,
spread=1.0,
set_op_mix_ratio=1.0,
local_connectivity=1,
repulsion_strength=1,
negative_sample_rate=5,
a=None,
b=None,
random_state=1234,
metric_kwds=None,
angular_rp_forest=False,
verbose=True)
embedding = reducer.fit_transform(adata_full.obsm['latent'])
adata_full.obsm["X_umap"] = embedding
adata_full.obs["slice"] = adata_full.obs["slice"].values.astype(str)
UMAP(angular_rp_forest=True, local_connectivity=1, metric='correlation', min_dist=0.3, n_neighbors=30, random_state=1234, repulsion_strength=1, verbose=True)
Wed May 28 19:41:28 2025 Construct fuzzy simplicial set
Wed May 28 19:41:28 2025 Finding Nearest Neighbors
Wed May 28 19:41:28 2025 Building RP forest with 12 trees
Wed May 28 19:41:30 2025 NN descent for 14 iterations
1 / 14
2 / 14
3 / 14
Stopping threshold met -- exiting after 3 iterations
Wed May 28 19:41:40 2025 Finished Nearest Neighbor Search
Wed May 28 19:41:42 2025 Construct embedding
completed 0 / 200 epochs
completed 20 / 200 epochs
completed 40 / 200 epochs
completed 60 / 200 epochs
completed 80 / 200 epochs
completed 100 / 200 epochs
completed 120 / 200 epochs
completed 140 / 200 epochs
completed 160 / 200 epochs
completed 180 / 200 epochs
Wed May 28 19:42:02 2025 Finished embedding
For visualizing UMAP plots, we utilizes the sc.pl.umap function from the Scanpy pipeline.
[12]:
sc.pl.umap(adata_full, color=["slice"])
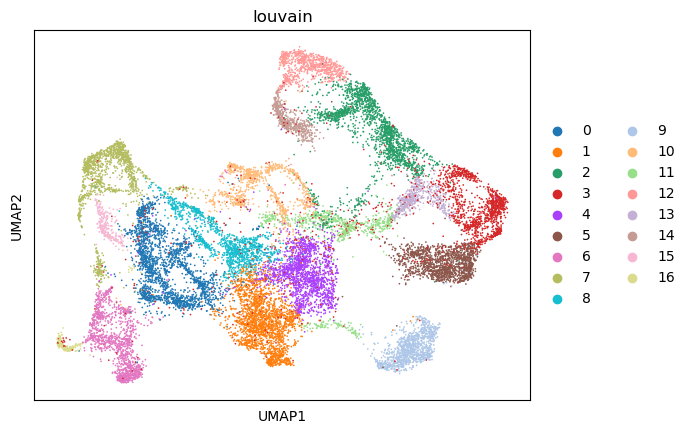
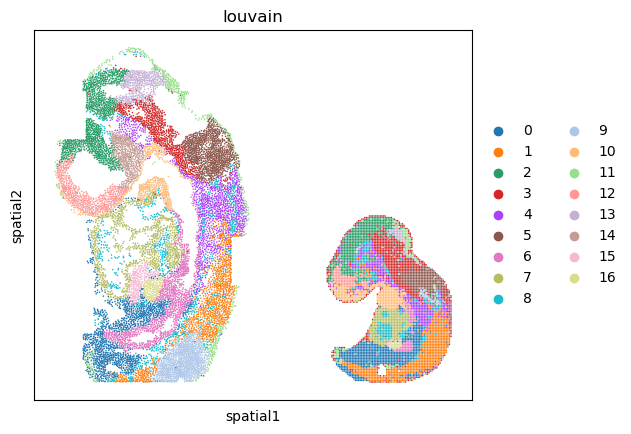
The learned spot representations enable the identification of spatial domains. When the number of spatial domains is known a priori, clustering is performed using a Gaussian Mixture Model implemented in the sklearn package. In the absence of such prior knowledge, spatial domains are identified using the Louvain clustering algorithm, implemented through the sc.pp.neighbors and sc.tl.louvain functions in the Scanpy package.
[13]:
sc.pp.neighbors(adata_full, use_rep="latent", n_neighbors=30)
sc.tl.louvain(adata_full, resolution=.7)
Spatial domain assignments are visualized on both the UMAP embedding and the spatial coordinates of the spots using the sc.pl.umap and sc.pl.spatial functions from the Scanpy pipeline, respectively.
[14]:
sc.pl.umap(adata_full, color=["louvain"])
sc.pl.spatial(adata_full, color=["louvain"], spot_size=1.)
Finally, we save the results from INSPIRE.
[15]:
res_path = "/gpfs/gibbs/pi/zhao/jz874/project/jiazhao/inspire_revision/tutorials/example_analyses/example_LGCN_data"
adata_full.write(res_path + "/adata_full_inspire.h5ad")
basis_df.to_csv(res_path + "/basis_df_inspire.csv")
[ ]: