Using INSPIRE with graph attention networks (GATs)
INSPIRE provides two integrative analyses options: one based on graph attention networks (GATs) and the other on lightweight graph convolutional networks (LGCNs). For tissue sections profiled using low-resolution platforms such as Visium or ST, we recommend employing the graph attention network variant of INSPIRE to leverage the attention mechanism for improved modeling accuracy. For high-resolution datasets, the lightweight graph convolutional network variant is recommended, as it provides enhanced computational efficiency and scalability for large-scale analyses.
We use the integrative analysis of human DLPFC Visium sections as an example to provide step-by-step instructions for applying INSPIRE with graph attention networks (GATs).
Import packages
[1]:
import numpy as np
import scanpy as sc
import umap
import INSPIRE
import warnings
warnings.filterwarnings("ignore")
Load data
The input to INSPIRE consists of raw gene expression count matrices and spatial coordinate matrices derived from multiple tissue sections, with each section represented as an individual AnnData object. Specifically, for each tissue section, the raw count matrix is stored in adata.X, and the spatial coordinates of the spatial spots are stored in adata.obsm[“spatial”].
The example Visium tissue sections used in this tutorial can be downloaded from https://drive.google.com/drive/folders/1viKSyC-KgkfEH481SLB-JKP4FThZtmLA?usp=sharing.
[2]:
data_dir = "/gpfs/gibbs/pi/zhao/jz874/project/jiazhao/inspire_revision/tutorials/example_analyses/example_GAT_data"
adata_1 = sc.read_h5ad(data_dir + "/adata_1.h5ad")
adata_2 = sc.read_h5ad(data_dir + "/adata_2.h5ad")
adata_3 = sc.read_h5ad(data_dir + "/adata_3.h5ad")
adata_4 = sc.read_h5ad(data_dir + "/adata_4.h5ad")
adata_st_list = [adata_1, adata_2, adata_3, adata_4]
Data preprocessing
INSPIRE uses a standard pipline adopted by Seurat and Scanpy to select highly variable genes as input features for data interpretation. In addition, it organizes the spatial positioning of multiple tissue sections to facilitate their joint visualization. Parameters in the INSPIRE.utils.preprocess function include: num_hvg, min_genes_qc, min_cell_qc, and spot_size. INSPIRE uses the intersection of highly variable genes across all sections as features for data modeling. By default, num_hvgs is set to 6,000. We recommend selecting approximately 2,000 to 3,000 shared highly variable genes to perform integrative analyses with INSPIRE. Users can customize quality control thresholds by adjusting min_genes_qc and min_cell_qc. Setting both parameters to 50 generally performs well for Visium datasets. The spot_size parameter is used only for visualization purposes and determines the size of each spot in the generated plots.
[3]:
adata_st_list, adata_full = INSPIRE.utils.preprocess(adata_st_list=adata_st_list,
num_hvgs=6000,
min_genes_qc=50,
min_cells_qc=50,
spot_size=100)
Finding highly variable genes...
shape of adata 0 before quality control: (3611, 33525)
shape of adata 0 after quality control: (3611, 13067)
shape of adata 1 before quality control: (3635, 33525)
shape of adata 1 after quality control: (3635, 13955)
shape of adata 2 before quality control: (3566, 33525)
shape of adata 2 after quality control: (3566, 12430)
shape of adata 3 before quality control: (3431, 33525)
shape of adata 3 after quality control: (3431, 12564)
Find 1857 shared highly variable genes among datasets.
Concatenate datasets as a full anndata for better visualization...

Store counts and library sizes for Poisson modeling...
Normalize data...
Build spaital graph
INSPIRE constructs a spatial neighbor graph among spots to account for spatial dependencies within each tissue section. When using the graph attention network (GAT) variant, this graph is generated via the INSPIRE.utils.build_graph_GAT function, which takes adata_st_list as input. For low-resolution tissue sections, the function first calculates the minimum distance between adjacent spots within each section and then multiplies this value by a scaling factor, rad_coef, to determine the radius cutoff for defining spatial neighbors. In practice, we set rad_coef to 1.1, which reliably captures natural neighborhood structures in Visium and ST datasets.
[4]:
adata_st_list = INSPIRE.utils.build_graph_GAT(adata_st_list=adata_st_list,
rad_coef=1.1)
Start building graphs...
Calculate radius cutoff based on 'rad_coef' and mininal distance between spots/cells within a dataset...
Radius for graph connection is 150.7000.
Build graphs for GAT networks
5.8261 neighbors per cell on average.
5.8140 neighbors per cell on average.
5.8015 neighbors per cell on average.
5.8193 neighbors per cell on average.
Run INSPIRE model
The computational model for the GAT variant of INSPIRE is constructed using the INSPIRE.model.Model_GAT function, which takes adata_st_list as input. Two key parameters for this function are n_spatial_factors and n_training_steps. The parameter n_spatial_factors determines the number of spatial factors to be inferred, and its value should be chosen based on the complexity of the tissue under analysis. As general guidelines, we recommend setting n_spatial_factors = 20 for regional tissue analysis, n_spatial_factors = 40 for whole-organ analyses, and n_spatial_factors = 60 for whole-organism analyses. The n_training_steps parameter specifies the total number of training iterations. A default setting of n_training_steps = 10,000 typically yields robust results, while increasing it to 20,000 may be beneficial when modeling with a large number of spatial factors.
[5]:
model = INSPIRE.model.Model_GAT(adata_st_list=adata_st_list,
n_spatial_factors=20,
n_training_steps=10000,
)
After constructing the computational model, training is performed using the model.train function.
[6]:
model.train()
0%| | 2/10000 [00:00<42:58, 3.88it/s]
Step: 0, d_loss: 4.1890, Loss: 6191.5420, recon_loss: 5737.2090, fe_loss: 153.9308, geom_loss: 1659.0681, beta_loss: 265.5975, gan_loss: 1.6235
5%|▌ | 502/10000 [01:11<22:31, 7.03it/s]
Step: 500, d_loss: 2.7276, Loss: 4500.6455, recon_loss: 4073.2205, fe_loss: 94.8756, geom_loss: 572.6364, beta_loss: 316.4294, gan_loss: 4.6677
10%|█ | 1002/10000 [02:22<21:23, 7.01it/s]
Step: 1000, d_loss: 2.7397, Loss: 3324.3406, recon_loss: 2865.2095, fe_loss: 94.4973, geom_loss: 507.4727, beta_loss: 350.1769, gan_loss: 4.3074
15%|█▌ | 1502/10000 [03:34<20:12, 7.01it/s]
Step: 1500, d_loss: 2.8014, Loss: 2606.3831, recon_loss: 2144.2754, fe_loss: 94.3163, geom_loss: 455.6437, beta_loss: 354.6157, gan_loss: 4.0627
20%|██ | 2002/10000 [04:45<19:03, 6.99it/s]
Step: 2000, d_loss: 2.7963, Loss: 2241.6333, recon_loss: 1789.3611, fe_loss: 94.1776, geom_loss: 428.7357, beta_loss: 345.8549, gan_loss: 3.6649
25%|██▌ | 2502/10000 [05:56<17:51, 7.00it/s]
Step: 2500, d_loss: 2.1069, Loss: 2064.5762, recon_loss: 1645.3214, fe_loss: 94.0392, geom_loss: 433.4143, beta_loss: 311.2199, gan_loss: 5.3274
30%|███ | 3002/10000 [07:08<16:39, 7.00it/s]
Step: 3000, d_loss: 1.8427, Loss: 1959.8378, recon_loss: 1565.1912, fe_loss: 93.9375, geom_loss: 453.5957, beta_loss: 285.9280, gan_loss: 5.7093
35%|███▌ | 3502/10000 [08:19<15:27, 7.01it/s]
Step: 3500, d_loss: 2.1460, Loss: 1890.9205, recon_loss: 1509.2654, fe_loss: 93.8111, geom_loss: 469.9376, beta_loss: 271.6135, gan_loss: 6.8317
40%|████ | 4002/10000 [09:31<14:17, 7.00it/s]
Step: 4000, d_loss: 1.5091, Loss: 1844.5392, recon_loss: 1477.9557, fe_loss: 93.6915, geom_loss: 486.3913, beta_loss: 256.4096, gan_loss: 6.7545
45%|████▌ | 4502/10000 [10:42<13:04, 7.01it/s]
Step: 4500, d_loss: 1.6537, Loss: 1817.4554, recon_loss: 1456.1819, fe_loss: 93.5770, geom_loss: 480.0478, beta_loss: 252.1498, gan_loss: 5.9460
50%|█████ | 5002/10000 [11:53<11:53, 7.01it/s]
Step: 5000, d_loss: 1.7657, Loss: 1797.6846, recon_loss: 1442.4232, fe_loss: 93.4767, geom_loss: 479.2017, beta_loss: 246.1289, gan_loss: 6.0718
55%|█████▌ | 5502/10000 [13:05<10:42, 7.00it/s]
Step: 5500, d_loss: 1.3964, Loss: 1786.9637, recon_loss: 1433.8008, fe_loss: 93.3614, geom_loss: 510.3692, beta_loss: 242.9444, gan_loss: 6.6498
60%|██████ | 6002/10000 [14:16<09:31, 7.00it/s]
Step: 6000, d_loss: 1.4576, Loss: 1779.2487, recon_loss: 1425.0194, fe_loss: 93.2731, geom_loss: 471.2994, beta_loss: 242.7296, gan_loss: 8.8005
65%|██████▌ | 6502/10000 [15:27<08:19, 7.00it/s]
Step: 6500, d_loss: 1.5057, Loss: 1770.5939, recon_loss: 1419.7565, fe_loss: 93.2283, geom_loss: 475.5424, beta_loss: 242.2359, gan_loss: 5.8623
70%|███████ | 7002/10000 [16:39<07:07, 7.01it/s]
Step: 7000, d_loss: 1.3497, Loss: 1767.0525, recon_loss: 1414.6483, fe_loss: 93.1958, geom_loss: 493.6393, beta_loss: 241.6638, gan_loss: 7.6717
75%|███████▌ | 7502/10000 [17:50<05:56, 7.00it/s]
Step: 7500, d_loss: 1.2755, Loss: 1761.2726, recon_loss: 1410.3046, fe_loss: 93.1438, geom_loss: 513.5750, beta_loss: 241.2229, gan_loss: 6.3298
80%|████████ | 8002/10000 [19:02<04:45, 7.01it/s]
Step: 8000, d_loss: 1.1530, Loss: 1759.3676, recon_loss: 1406.7915, fe_loss: 93.0756, geom_loss: 485.0925, beta_loss: 241.2306, gan_loss: 8.5678
85%|████████▌ | 8502/10000 [20:13<03:34, 7.00it/s]
Step: 8500, d_loss: 1.3925, Loss: 1756.7133, recon_loss: 1404.2229, fe_loss: 93.0348, geom_loss: 508.4655, beta_loss: 241.6235, gan_loss: 7.6627
90%|█████████ | 9002/10000 [21:24<02:22, 7.00it/s]
Step: 9000, d_loss: 1.1445, Loss: 1755.2981, recon_loss: 1402.1340, fe_loss: 92.9919, geom_loss: 509.8484, beta_loss: 241.4175, gan_loss: 8.5576
95%|█████████▌| 9502/10000 [22:36<01:11, 7.00it/s]
Step: 9500, d_loss: 0.9016, Loss: 1752.5907, recon_loss: 1399.8112, fe_loss: 92.9360, geom_loss: 547.9695, beta_loss: 241.2215, gan_loss: 7.6627
100%|██████████| 10000/10000 [23:47<00:00, 7.01it/s]
Access spot representations, proportions of spatial factors in spots, and gene loading matrix
After training the model, INSPIRE infers latent representations of spatial spots, spatial factors, and gene loadings using the model.eval function. This function returns two main outputs: adata_full and basis_df. The inferred latent representations of spatial spots are stored in adata_full.obsm[‘latent’], while the metadata indicating the section origin of each spot is saved in adata_full.obs. The spatial factor values assigned to individual spots are also stored in adata_full.obs, where adata_full.obs[“Proportion of spatial factor i”] contains the proportion values corresponding to spatial factor i across all analyzed spots. The inferred gene loading matrix, shared across sections, is saved in basis_df, which is a data frame with spatial factors as rows and genes as columns.
[7]:
adata_full, basis_df = model.eval(adata_full)
basis = np.array(basis_df.values)
Add cell/spot proportions of spatial factors into adata_full.obs...
Add cell/spot latent representations into adata_full.obsm['latent']...
[8]:
basis_df
[8]:
| AACS | AAK1 | AASDHPPT | ABCA2 | ABCB1 | ABHD13 | ABHD17B | ABI1 | AC004158.1 | AC005944.1 | ... | ZNF667 | ZNF682 | ZNF684 | ZNF74 | ZNF92 | ZNHIT6 | ZNRD1 | ZSCAN29 | ZSWIM6 | ZYG11B | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000526 | 0.000810 | 0.000627 | 0.000590 | 0.000120 | 0.000428 | 0.000588 | 0.000421 | 0.000220 | 0.000249 | ... | 0.000804 | 0.000497 | 0.000120 | 0.000200 | 0.000612 | 0.000390 | 0.000191 | 0.000216 | 0.000407 | 0.000836 |
| 1 | 0.000685 | 0.000663 | 0.000556 | 0.000289 | 0.000380 | 0.000325 | 0.000303 | 0.000451 | 0.000221 | 0.000315 | ... | 0.000441 | 0.000174 | 0.000114 | 0.000232 | 0.000268 | 0.000388 | 0.000537 | 0.000194 | 0.000270 | 0.000654 |
| 2 | 0.000371 | 0.000844 | 0.000643 | 0.000384 | 0.000317 | 0.000490 | 0.000293 | 0.000436 | 0.000208 | 0.001974 | ... | 0.000531 | 0.000536 | 0.000201 | 0.000373 | 0.000305 | 0.000675 | 0.000355 | 0.000523 | 0.000327 | 0.000544 |
| 3 | 0.000720 | 0.000713 | 0.000554 | 0.000327 | 0.000420 | 0.000436 | 0.000335 | 0.000439 | 0.000181 | 0.000298 | ... | 0.000360 | 0.000182 | 0.000311 | 0.000436 | 0.000277 | 0.000324 | 0.000349 | 0.000259 | 0.000289 | 0.000735 |
| 4 | 0.000381 | 0.000567 | 0.000469 | 0.000466 | 0.000215 | 0.000748 | 0.000426 | 0.000458 | 0.000299 | 0.000328 | ... | 0.000485 | 0.000479 | 0.000502 | 0.000464 | 0.000315 | 0.000513 | 0.000416 | 0.000386 | 0.000455 | 0.000759 |
| 5 | 0.000469 | 0.000535 | 0.000513 | 0.000553 | 0.000521 | 0.000521 | 0.000870 | 0.000236 | 0.001019 | 0.000120 | ... | 0.000211 | 0.000237 | 0.000217 | 0.000564 | 0.000430 | 0.000201 | 0.000517 | 0.000258 | 0.000235 | 0.000671 |
| 6 | 0.000763 | 0.000925 | 0.000389 | 0.000365 | 0.000277 | 0.000298 | 0.000484 | 0.000429 | 0.000122 | 0.000332 | ... | 0.000428 | 0.000267 | 0.000309 | 0.000499 | 0.000224 | 0.000424 | 0.000647 | 0.000196 | 0.000286 | 0.000681 |
| 7 | 0.000607 | 0.001029 | 0.000713 | 0.000286 | 0.000361 | 0.000394 | 0.000481 | 0.000294 | 0.000321 | 0.000460 | ... | 0.000377 | 0.000416 | 0.000336 | 0.000290 | 0.000283 | 0.000395 | 0.000174 | 0.000303 | 0.000286 | 0.000772 |
| 8 | 0.000580 | 0.000797 | 0.000717 | 0.000386 | 0.000752 | 0.000401 | 0.000321 | 0.000601 | 0.000175 | 0.001562 | ... | 0.000329 | 0.000167 | 0.000076 | 0.000445 | 0.000173 | 0.000405 | 0.000429 | 0.000395 | 0.000389 | 0.000667 |
| 9 | 0.000575 | 0.000747 | 0.000579 | 0.000289 | 0.000396 | 0.000215 | 0.000461 | 0.000386 | 0.000132 | 0.001125 | ... | 0.000377 | 0.000325 | 0.000187 | 0.000117 | 0.000615 | 0.000408 | 0.000349 | 0.000517 | 0.000259 | 0.000735 |
| 10 | 0.000891 | 0.000734 | 0.000703 | 0.000199 | 0.000155 | 0.000493 | 0.000308 | 0.000347 | 0.000181 | 0.001066 | ... | 0.000526 | 0.000315 | 0.000299 | 0.000343 | 0.000153 | 0.000338 | 0.000168 | 0.000227 | 0.000449 | 0.000754 |
| 11 | 0.000388 | 0.000428 | 0.000159 | 0.000322 | 0.000292 | 0.000677 | 0.000228 | 0.000746 | 0.000347 | 0.000629 | ... | 0.000515 | 0.000211 | 0.000102 | 0.000733 | 0.000099 | 0.000287 | 0.000617 | 0.000469 | 0.000286 | 0.000278 |
| 12 | 0.000170 | 0.000153 | 0.000226 | 0.002353 | 0.000152 | 0.000147 | 0.001191 | 0.000241 | 0.000668 | 0.000083 | ... | 0.000082 | 0.000210 | 0.000317 | 0.000217 | 0.000300 | 0.000697 | 0.000409 | 0.000375 | 0.000809 | 0.000165 |
| 13 | 0.000646 | 0.000634 | 0.000566 | 0.000349 | 0.000452 | 0.000289 | 0.000282 | 0.000406 | 0.000360 | 0.000270 | ... | 0.000217 | 0.000342 | 0.000517 | 0.000274 | 0.000457 | 0.000603 | 0.000227 | 0.000164 | 0.000488 | 0.000861 |
| 14 | 0.000507 | 0.000983 | 0.000654 | 0.000391 | 0.000229 | 0.000387 | 0.000226 | 0.000403 | 0.000190 | 0.001442 | ... | 0.000219 | 0.000177 | 0.000856 | 0.000321 | 0.000418 | 0.000188 | 0.000164 | 0.000269 | 0.000310 | 0.000494 |
| 15 | 0.000505 | 0.000692 | 0.000647 | 0.000188 | 0.000234 | 0.000350 | 0.000300 | 0.000217 | 0.000181 | 0.000236 | ... | 0.000311 | 0.000258 | 0.000244 | 0.000254 | 0.000264 | 0.000325 | 0.000210 | 0.000268 | 0.000230 | 0.000533 |
| 16 | 0.000658 | 0.000753 | 0.000737 | 0.000308 | 0.000186 | 0.000689 | 0.000329 | 0.000487 | 0.000126 | 0.000333 | ... | 0.000453 | 0.000096 | 0.000180 | 0.000512 | 0.000417 | 0.000285 | 0.000214 | 0.000116 | 0.000190 | 0.000976 |
| 17 | 0.000518 | 0.000786 | 0.000851 | 0.000339 | 0.000242 | 0.000519 | 0.000177 | 0.000770 | 0.000060 | 0.000199 | ... | 0.000853 | 0.000247 | 0.000170 | 0.000323 | 0.000463 | 0.000310 | 0.000278 | 0.000478 | 0.000333 | 0.000734 |
| 18 | 0.000548 | 0.000803 | 0.000585 | 0.000405 | 0.000296 | 0.000502 | 0.000380 | 0.000282 | 0.000167 | 0.000298 | ... | 0.000230 | 0.000346 | 0.000102 | 0.000423 | 0.000254 | 0.000261 | 0.000401 | 0.000323 | 0.000396 | 0.000868 |
| 19 | 0.000846 | 0.000904 | 0.000785 | 0.000209 | 0.000228 | 0.000476 | 0.000323 | 0.000293 | 0.000040 | 0.000730 | ... | 0.000268 | 0.000260 | 0.000374 | 0.000523 | 0.000598 | 0.000387 | 0.000241 | 0.000126 | 0.000107 | 0.000956 |
20 rows × 1857 columns
Spatial distributions of spatial factors in tissues
The proportion values corresponding to spatial factors across all analyzed spots are stored in adata_full.obs. These spatial patterns can be visualized using the sc.pl.spatial function from the Scanpy pipeline. The spot_size parameter controls the size of each spatial spot in the resulting plots.
[9]:
sc.pl.spatial(adata_full, color=["Proportion of spatial factor "+str(i+1) for i in range(20)], spot_size=150.)

Spot representations and spatial domain identification
To visualize the spot representations learned by INSPIRE, we employ UMAP plots. The UMAP embedding is generated by first constructing a UMAP model using umap.UMAP, and then transforming the spot representations into two-dimensional coordinates using the fit_transform function from the umap package.
[10]:
# calculate 2D UMAP coordinate of spots based on INSPIRE's learned spot representations.
reducer = umap.UMAP(n_neighbors=30,
n_components=2,
metric="correlation",
n_epochs=None,
learning_rate=1.0,
min_dist=0.3,
spread=1.0,
set_op_mix_ratio=1.0,
local_connectivity=1,
repulsion_strength=1,
negative_sample_rate=5,
a=None,
b=None,
random_state=1234,
metric_kwds=None,
angular_rp_forest=False,
verbose=True)
embedding = reducer.fit_transform(adata_full.obsm['latent'])
adata_full.obsm["X_umap"] = embedding
adata_full.obs["slice"] = adata_full.obs["slice"].values.astype(str)
UMAP(angular_rp_forest=True, local_connectivity=1, metric='correlation', min_dist=0.3, n_neighbors=30, random_state=1234, repulsion_strength=1, verbose=True)
Wed May 28 19:41:41 2025 Construct fuzzy simplicial set
Wed May 28 19:41:41 2025 Finding Nearest Neighbors
Wed May 28 19:41:41 2025 Building RP forest with 11 trees
Wed May 28 19:41:44 2025 NN descent for 14 iterations
1 / 14
2 / 14
Stopping threshold met -- exiting after 2 iterations
Wed May 28 19:41:52 2025 Finished Nearest Neighbor Search
Wed May 28 19:41:54 2025 Construct embedding
completed 0 / 200 epochs
completed 20 / 200 epochs
completed 40 / 200 epochs
completed 60 / 200 epochs
completed 80 / 200 epochs
completed 100 / 200 epochs
completed 120 / 200 epochs
completed 140 / 200 epochs
completed 160 / 200 epochs
completed 180 / 200 epochs
Wed May 28 19:42:07 2025 Finished embedding
For visualizing UMAP plots, we utilizes the sc.pl.umap function from the Scanpy pipeline.
[11]:
sc.pl.umap(adata_full, color=["layer", "slice"])
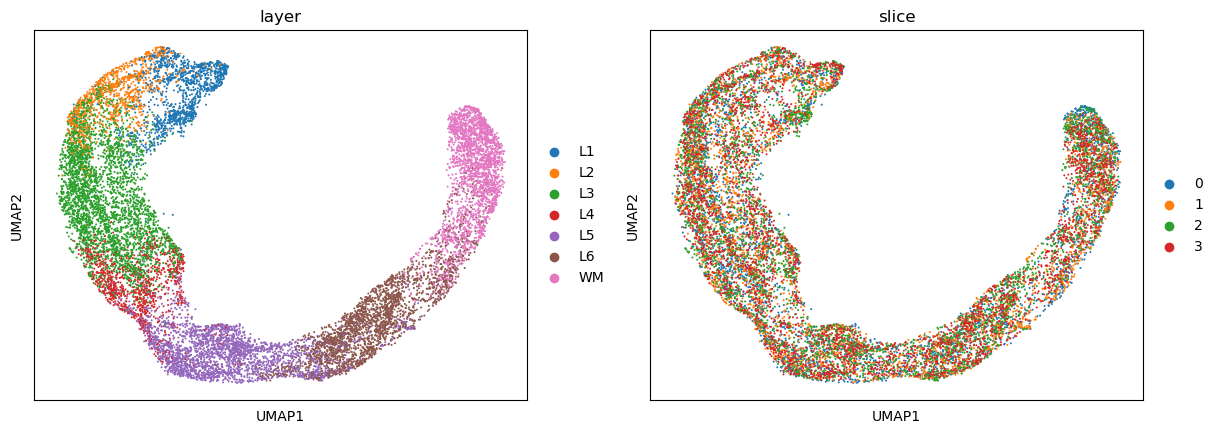
The learned spot representations facilitate the identification of spatial domains. In this example, given prior knowledge of the number of ground-truth spatial regions, we apply a Gaussian Mixture Model, as implemented in the sklearn package, to perform clustering.
[12]:
from sklearn.mixture import GaussianMixture
np.random.seed(1234)
gm = GaussianMixture(n_components=7, covariance_type='tied', init_params='kmeans')
y = gm.fit_predict(adata_full.obsm['latent'], y=None)
adata_full.obs["GM"] = y
Spatial domain assignments are visualized on both the UMAP embedding and the spatial coordinates of the spots using the sc.pl.umap and sc.pl.spatial functions from the Scanpy pipeline, respectively.
[13]:
sc.pl.umap(adata_full, color=["GM"])
sc.pl.spatial(adata_full, color=["GM"], spot_size=150.)
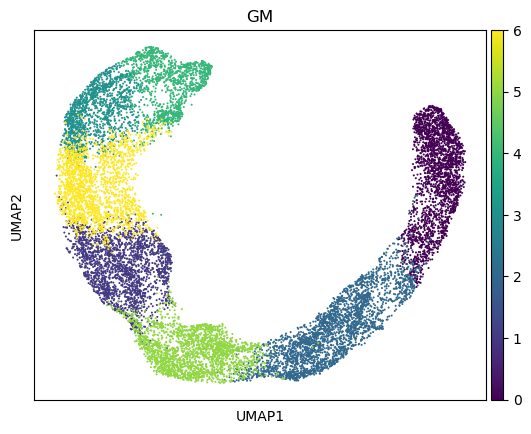
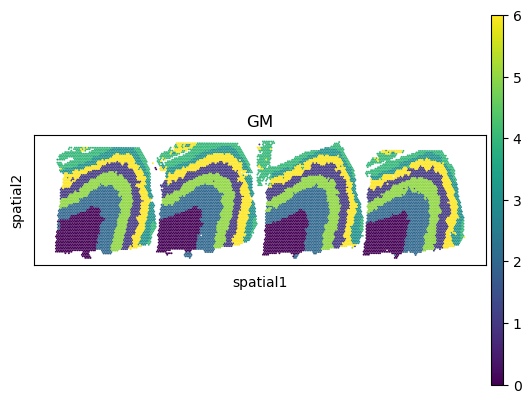
Finally, we save the results from INSPIRE.
[14]:
res_path = "/gpfs/gibbs/pi/zhao/jz874/project/jiazhao/inspire_revision/tutorials/example_analyses/example_GAT_data"
adata_full.write(res_path + "/adata_full_inspire.h5ad")
basis_df.to_csv(res_path + "/basis_df_inspire.csv")
[ ]: